


Transformer Model, A Paradigm Shift in NLP and Machine Translation
Farhad Reyazat -London School of Banking and Finance
Citation: Reyazat, F. (2024, April 7). Transformer Model, A paradigm shift in NLP and Machine Translation. Dr. Farhad Reyazat. https://www.reyazat.com/2024/04/07/transformer-model-nlp-shift/
Introduction
In the swiftly evolving domain of artificial intelligence, natural language processing (NLP) and machine translation have marked significant milestones, owing much of their progress to groundbreaking models like the Transformer. Introduced in the seminal paper “Attention Is All You Need” by Vaswani et al. in 2017, the Transformer model has reshaped our approach to processing language computationally, moving beyond the constraints that once limited the scope of machine learning applications in linguistics. This recap review delves deep into the Transformer architecture, unpacking its components, functionalities, and vast implications on the NLP field.
The Limitations of RNNs and LSTMs in NLP
- The Era of Sequential Data Processing
For a considerable period, Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), a sophisticated extension of RNNs, were celebrated as the pinnacle of machine learning technologies for processing sequential data. These models have been instrumental in pioneering efforts to understand and generate human language, playing a critical role in the development of technologies ranging from machine translation to voice recognition systems. RNNs, with their ability to process sequences of data by looping information through the network, seemed like an ideal fit for tasks that required an understanding of language over time.
- Core Limitations of RNNs and LSTMs
Despite their initial promise, RNNs and LSTMs have encountered significant hurdles that have impeded their effectiveness and efficiency in handling complex language tasks:
1. Sequential Processing and Computational Speed: At the heart of the issue is the sequential processing nature of RNNs and LSTMs. Each piece of input data must be processed one after the other, creating a bottleneck that drastically slows down computation. This inherent characteristic makes it challenging to leverage modern parallel computing technologies, such as GPUs, which are designed to perform many operations simultaneously, thus limiting the scalability and speed of training and inference processes.
2. Vanishing Gradient Problem: A notorious challenge in training deep neural networks, the vanishing gradient problem, is particularly acute in RNNs and LSTMs. As these networks learn, gradients—the parameters used to adjust the network’s weights—are propagated back through the network. However, in long sequences, these gradients can become exceedingly small (vanish), making it nearly impossible for the network to learn and adjust, thereby stalling the learning process. This issue complicates the training of RNNs and LSTMs, especially for tasks requiring the understanding of long texts or sequences.
3.Difficulty in Capturing Long-Range Dependencies: Language is inherently complex, with meaning often dependent on long-range dependencies. For example, the subject of a sentence at the beginning may determine the verb form used at the end. RNNs and LSTMs struggle to maintain and leverage information over long sequences, thereby limiting their ability to grasp the full context of language inputs. This limitation hampers their effectiveness in tasks such as language modeling and machine translation, where understanding the broader context is crucial for accurate output.
Beyond the Limitations: The Search for Solutions
The limitations of RNNs and LSTMs have prompted researchers to explore new architectures and methodologies. Innovations such as Gated Recurrent Units (GRUs) were introduced as a simpler alternative to LSTMs, aiming to mitigate some of the challenges while maintaining the ability to process sequential data. Moreover, the advent of attention mechanisms and the Transformer model has provided a groundbreaking alternative, enabling models to directly focus on different parts of the input sequence without being constrained by the sequential nature of RNNs and LSTMs. These models have shown superior performance in capturing long-range dependencies and significantly faster training times due to their inherent parallelizability.
The exploration of RNNs and LSTMs has been a pivotal chapter in the advancement of natural language processing, offering deep insights into the complexities of sequential data processing. While their limitations have prompted the search for more efficient and effective models, the lessons learned from the deployment of RNNs and LSTMs continue to influence the development of new neural network architectures. Today, as we stand on the brink of new discoveries in NLP, the legacy of RNNs and LSTMs endures, reminding us of the iterative nature of scientific progress and the continuous quest for models that can more deeply understand and generate human language.in text, which is crucial for understanding the context and semantics in language tasks.
The Advent of the Transformer Model
Addressing the challenges above, the Transformer model, as proposed by Vaswani and colleagues, introduced a paradigm shift with its unique architecture centered around self-attention mechanisms. This innovation offered a novel approach to understanding textual data, emphasizing key features that set it apart:
Image: The Transformer – model architecture
- Self-Attention Mechanism: At its core, the Transformer model utilizes self-attention to process all input tokens in parallel. This mechanism allows each token to interact with every other token in the input sequence, effectively understanding the context and nuances of language beyond sequential analysis.
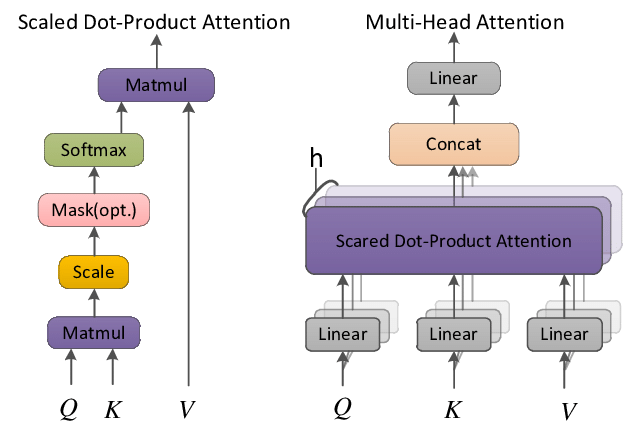
2. Multi-Head Attention: By employing multiple attention “heads,” the Transformer can capture various aspects and relationships within the data, enhancing its ability to understand complex patterns and dependencies. This is achieved through simultaneous attention processes that are later concatenated and transformed, enriching the model’s comprehension of the input.
3. Positional Encoding: To account for the order of words without relying on sequential data processing, the Transformer incorporates positional encodings. These encodings are added to the input embeddings, imbuing the model with the necessary context regarding the position of each token within the sequence.
4. Encoder and Decoder Stacks: Comprising multiple layers of encoders and decoders, the Transformer architecture processes the input and generates output in a structured manner. Each layer in these stacks consists of self-attention and feed-forward neural networks designed to refine the input-output mapping progressively.
5. Residual Connections and Layer Normalization: Enhancing the flow of gradients and ensuring stability during training, residual connections, and layer normalization are critical components of the Transformer model. They facilitate smoother training dynamics and contribute to the robustness of the model.
Training, Inference, and Applications
The training phase of the Transformer involves learning to focus on relevant tokens and creating context-aware representations. In contrast, the inference phase uses autoregressive decoding to generate outputs based on the previously produced tokens. This advanced modeling has led to unprecedented performance across various NLP tasks:
– Machine Translation: Demonstrating superior performance on benchmarks like the WMT 2014 English-German translation task, the Transformer model set new standards for accuracy and efficiency in machine translation.
– Language Modeling: In language modeling benchmarks, Transformers have showcased their ability to predict subsequent words in a sequence with remarkable precision, leading to more fluent and coherent text generation.
– Question Answering: With the advent of Transformer-based models like BERT, the capabilities to understand and respond to complex questions have significantly improved, marking a leap forward in machine comprehension.
The paper “Attention Is All You Need” by Vaswani et al., published in 2017, marks a watershed moment in the field of natural language processing (NLP) and machine learning. It introduced the Transformer model, which has since become the foundation for many state-of-the-art NLP models, including BERT, GPT, and T5. The significance of the article and the model it proposes cannot be overstated, but like all pioneering research, it has its strengths and weaknesses.
Strengths
1. Introduction of the Transformer Model: The paper’s most significant contribution is the Transformer model itself, which introduced a novel approach to sequence-to-sequence tasks without relying on recurrent layers. This dramatically improved computational efficiency and training times.
2. Self-Attention Mechanism: The model’s use of self-attention mechanisms allows it to weigh the importance of different words in a sentence, enabling it to capture complex linguistic structures and dependencies better than previous models. This ability to understand the context and relationships within the text has significantly advanced performance in NLP tasks.
3. Parallel Processing: Unlike RNNs and LSTMs, the Transformer allows for much greater parallelization during training, leading to much faster training times. This is largely because it processes data in batches, rather than sequentially, which leverages modern GPU architectures more effectively.
4. State-of-the-Art Performance: At the time of its publication, the Transformer model achieved state-of-the-art results on several benchmarks, including machine translation and other NLP tasks. This demonstrated not only the theoretical importance of the model but also its practical effectiveness.
5. Inspiration for Subsequent Research: The Transformer has inspired a plethora of subsequent research and models, leading to significant advancements in NLP. Its architecture is the backbone of many models that have pushed the boundaries of what’s possible in language understanding and generation.
Weaknesses
1. Resource Intensity: One criticism of the Transformer model, and indeed the models it inspired, is the significant computational resources required for training. Models based on the Transformer architecture often require extensive GPU hours and large datasets, which can be a barrier to entry for some researchers and institutions.
2. Interpretability and Complexity: While the Transformer has improved NLP performance, its complex architecture can be challenging to interpret and understand, especially compared to simpler models. This complexity can make it difficult to diagnose issues or understand why the model makes certain decisions.
3. Overfitting on Large Datasets: The Transformer’s capacity for parallel processing and handling large datasets also comes with an increased risk of overfitting, especially when trained on smaller datasets without proper regularization or data augmentation techniques.
4. Generalization to Other Domains: While incredibly effective for NLP, the Transformer’s application to domains outside of language processing has been less straightforward. Adaptations are often necessary to achieve similar success in areas like computer vision or audio processing.
Conclusion
With its innovative self-attention mechanism and parallel processing capabilities, the Transformer model has indelibly transformed the landscape of NLP and machine translation. Its development addressed the limitations of previous models and opened up new avenues for exploration and advancement in the field. The success of the Transformer has inspired a plethora of subsequent models, such as BERT, GPT, and T5, each building on its foundational principles to enhance further our ability to process and understand language. As we continue to explore and refine these models, the Transformer is a pivotal achievement in the ongoing journey of deep learning research, signifying a milestone in our quest to decode the complexities of human language.
Sources:
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All You Need. https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html




2 replies on “Transformer Model, A Paradigm Shift in NLP and Machine Translation”
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you, your article surprised me, there is such an excellent point of view. Thank you for sharing, I learned a lot.